
Suppose that the human genome has 30,000 distinct genes, which we will label as i = 1,2, ... N, where N = 30k. Next, suppose that there are n_i variants or alleles (mutations) of the i-th gene. Then, each human's genetic information can be described as a point on a lattice of size n_1 x n_2 x n_3 ... n_N, or equivalently an N-tuple of integers, each of whose values range from 1 to n_i. For the simplified case where there are exactly 10 variants of each gene, the number of points in this N dimensional space is 10^N or 10^{30k}, one for each distinct 30k digit number. It's a space of very high dimension, but this doesn't stop us from defining a metric, or measure of distance between any two points in the space. (For simplicity we ignore restrictions on this space which might result from incompatibility of certain combinations, etc.)
Note that the genomes of all of the humans who have ever lived occupy only a small subset of this space -- most possible variations have never been realized. For this reason, the surprise expressed by biologists that humans have so few genes (not many more than a worm, and far less than the 100k of earlier estimates) is no cause for concern -- the number of possible organisms that might result from 30k genes is enormous -- far more than the number of molecules in the visible universe.
To define a metric, we need a notion of how far apart two different alleles are. We can do this by counting base pair differences -- most mutations only alter a few base pairs in the genetic code. We can define the distance between two alleles in terms of the number of base pair changes between them (this is always a positive number). Then, we can define the distance between two genomes as the sum of each of the i=1,2,..,N individual gene distances. It is natural, although perhaps not always possible, to choose the n_i labeling of alleles to reflect relative distances, so variants n_1 and n_2 are close together, and both very far from n_10.
The exact definition of the metric and the allele labeling are somewhat arbitrary, but you can see it is easy to define a meaningful measure of how far apart any two individuals are in genome space.
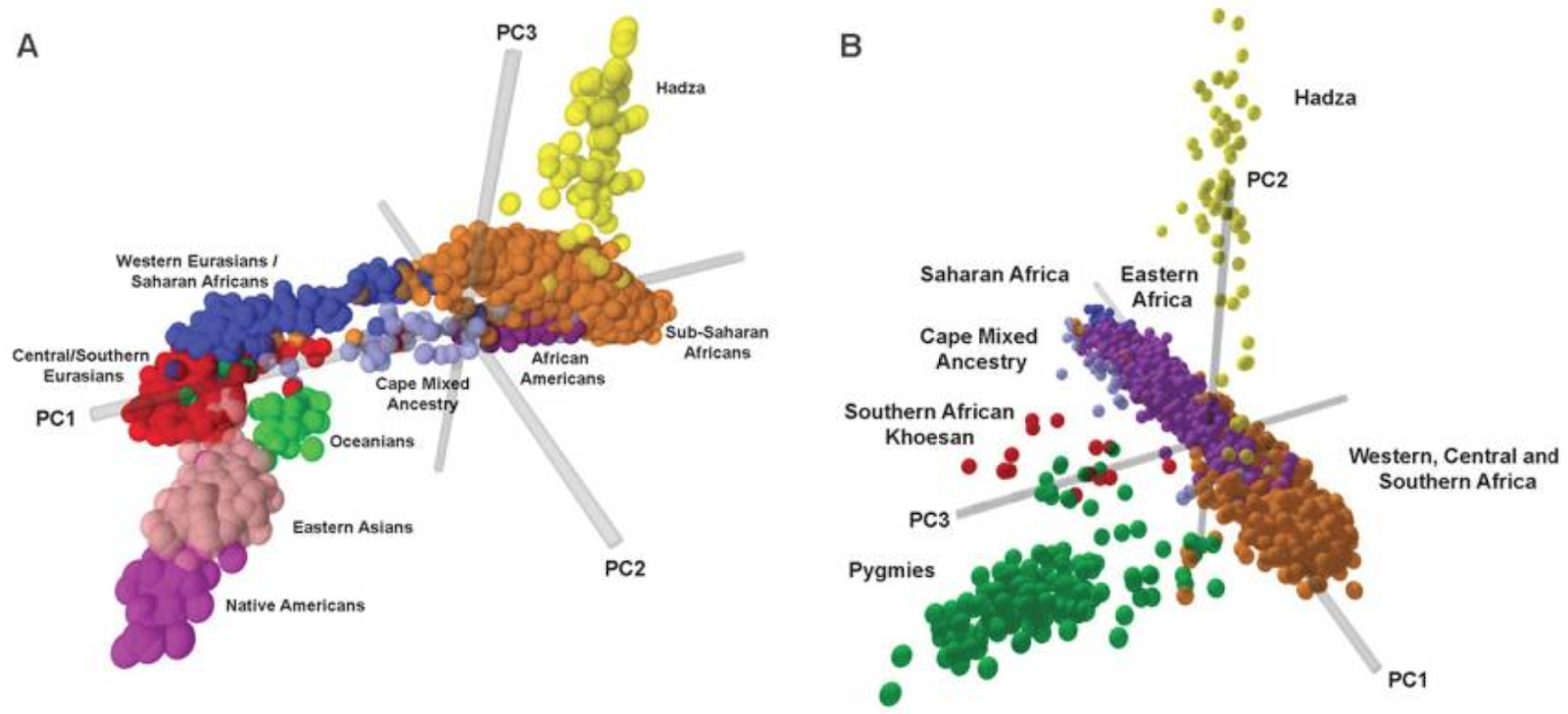
Now plot the genome of each human as a point on our lattice. Not surprisingly, there are readily identifiable clusters of points, corresponding to traditional continental ethnic groups: Europeans, Africans, Asians, Native Americans, etc. (See, for example, Risch et al., Am. J. Hum. Genet. 76:268–275, 2005.) Of course, we can get into endless arguments about how we define European or Asian, and of course there is substructure within the clusters, but it is rather obvious that there are identifiable groupings, and as the Risch study shows, they correspond very well to self-identified notions of race.
From the conclusions of the Risch paper (Am. J. Hum. Genet. 76:268–275, 2005):
Attention has recently focused on genetic structure in the human population. Some have argued that the amount of genetic variation within populations dwarfs the variation between populations, suggesting that discrete genetic categories are not useful (Lewontin 1972; Cooper et al. 2003; Haga and Venter 2003). On the other hand, several studies have shown that individuals tend to cluster genetically with others of the same ancestral geographic origins (Mountain and Cavalli-Sforza 1997; Stephens et al. 2001; Bamshad et al. 2003). Prior studies have generally been performed on a relatively small number of individuals and/or markers. A recent study (Rosenberg et al. 2002) examined 377 autosomal micro-satellite markers in 1,056 individuals from a global sample of 52 populations and found significant evidence of genetic clustering, largely along geographic (continental) lines. Consistent with prior studies, the major genetic clusters consisted of Europeans/West Asians (whites), sub-Saharan Africans, East Asians, Pacific Islanders, and Native Americans. ... We have shown a nearly perfect correspondence between genetic cluster and SIRE [self-reported ethnicity] for major ethnic groups living in the United States, with a discrepancy rate of only 0.14%.
This clustering is a natural consequence of geographical isolation, inheritance and natural selection operating over the last 50k years since humans left Africa.
Every allele probably occurs in each ethnic group, but with varying frequency. Suppose that for a particular gene there are 3 common variants (v1, v2, v3) all the rest being very rare. Then, for example, one might find that in ethnic group A the distribution is v1 75%, v2 15%, v3 10%, while for ethnic group B the distribution is v1 2% v2 6% v3 92%. Suppose this pattern is repeated for several genes, with the common variants in population A being rare in population B, and vice versa. Then, one might find a very dramatic difference in expressed phenotype between the two populations. For example, if skin color is determined by (say) 10 genes, and those genes have the distribution pattern given above, nearly all of population A might be fair skinned while all of population B is dark, even though there is complete overlap in the set of common alleles. Perhaps having the third type of variant v3 in 7 out of 10 pigmentation genes makes you dark. This is highly likely for an individual in population B with the given probabilities, but highly unlikely in population A.
We see that there can be dramatic group differences in phenotypes even if there is complete allele overlap between two groups - as long as the frequency or probability distributions are distinct. But it is these distributions that are measured by the metric we defined earlier. Two groups that form distinct clusters are likely to exhibit different frequency distributions over various genes, leading to group differences.
This leads us to two very different possibilities in human genetic variation:
Hypothesis 1: (the PC mantra) The only group differences that exist between the clusters (races) are innocuous and superficial, for example related to skin color, hair color, body type, etc.
Hypothesis 2: (the dangerous one) Group differences exist which might affect important (let us say, deep rather than superficial) and measurable characteristics, such as cognitive abilities, personality, athletic prowess, etc.
Note H1 is under constant revision, as new genetically driven group differences (e.g., particularly in disease resistance) are being discovered. According to the mantra of H1 these must all (by definition) be superficial differences.
A standard argument against H2 is that the 50k years during which groups have been separated is not long enough for differential natural selection to cause any group differences in deep characteristics. I find this argument quite naive, given what we know about animal breeding and how evolution has affected the (ever expanding list of) "superficial" characteristics. Many genes are now suspected of having been subject to strong selection over timescales of order 5k years or less. For further discussion of H2 by Steve Pinker, see here.
The predominant view among social scientists is that H1 is obviously correct and H2 obviously false. However, this is mainly wishful thinking. Official statements by the American Sociological Association and the American Anthropological Association even endorse the view that race is not a valid biological concept, which is clearly incorrect.
As scientists, we don't know whether H1 or H2 is correct, but given the revolution in biotechnology, we will eventually. Let me reiterate, before someone labels me a racist: we don't know with high confidence whether H1 or H2 is correct.
Finally, it is important to note that group differences are statistical in nature and do not imply anything definitive about a particular individual. Rather than rely on the scientifically unsupported claim that we are all equal, it would be better to emphasize that we all have inalienable human rights regardless of our abilities or genetic makeup.
[See here (Economist's View blog) for more comments.]
[See Gene Expression for more discussion and references.]
Note added: See related Risch article which discusses H1 and H2: Assessing genetic contributions to phenotypic differences among 'racial' and 'ethnic' groups (Nature 2004), and also these 2013 comments in an interview with Ta-Nehisi Coates for The Atlantic:
Q: One last question. Your paper on assessing genetic contributions to phenotype, seemed skeptical that we would ever tease out a group-wide genetic component when looking at things like cognitive skills or personality disposition. Am I reading that right? Are "intelligence" and "disposition" just too complicated?To repeat, I think it is fair to say that we don't know*** whether H1 or H2 is correct, even though we do know that populations cluster (genetically) by ancestry. Clustering makes it possible that H2 is correct, because the alleles (genetic variants) affecting a particular phenotype will tend to have different frequencies in different groups. The average value of the trait might or might not be the same in different groups. In the case of height, enough is known to suggest that variants which lead to increased height are more frequent in northern Europe than in the south, and there is evidence that this is due to selection, not drift.
A: (Risch) Joanna Mountain and I tried to explain this in our Nature Genetics paper on group differences. It is very challenging to assign causes to group differences. As far as genetics goes, if you have identified a particular gene which clearly influences a trait, and the frequency of that gene differs between populations, that would be pretty good evidence. But traits like "intelligence" or other behaviors (at least in the normal range), to the extent they are genetic, are "polygenic." That means no single genes have large effects -- there are many genes involved, each with a very small effect. Such gene effects are difficult if not impossible to find. The problem in assessing group differences is the confounding between genetic and social/cultural factors. If you had individuals who are genetically one thing but socially another, you might be able to tease it apart, but that is generally not the case.
In our paper, we tried to show that a trait can appear to have high "genetic heritability" in any particular population, but the explanation for a group difference for that trait could be either entirely genetic or entirely environmental or some combination in between.
So, in my view, at this point, any comment about the etiology of group differences, for "intelligence" or anything else, in the absence of specific identified genes (or environmental factors, for that matter), is speculation.
*** I think it's especially important to be epistemologically careful in thinking about these matters, because of our difficult history with race. I would much rather live in a world where H1 is true and H2 false. But my preference alone does not make it so. (I would also much rather live in a universe created by a loving God, and in which I and my children have eternal souls; not a cruel Darwinian universe in which our species arose merely by chance. But my preference does not make it so.)
24 comments:
very dangerous indeed.
Interesting.
However, a priori, why should genes responsible for skin pigmentation(for example) have anything to do with intelligence/atheletic ability etc? Are the genes the same? In principle, they need not be.
Of course, one can always define what a "cluster" (or "people group")is by simply geouping people with one characteristic, i.e., there exists disjoint groups differing in one charateristic. However, in principle (and I suspect), a different clustering will exist for a different trait. As one adds more and more characteristics, I do not see how skin pigmentation(or any other kind of) grouping will not be that useful a concept. And inter-breeding will muddy the situation even further.
Therefore, a priori, I still do not see why race (or any type of cluster) will be a very useful concept.
I would agree that H2 holds if one can show that the genes responsible for skin pigmentation(or other such attributes) is the SAME as that for intelligence/atheletic ability, etc... The odds are low, I think.
I suppose "on the average" there could be differences, but then it is purely chance, and hard to distinguish from external environment (such as opportunities, socital value of traits, etc). For instance, in a different "Earth" in the landscape of universe there will be a completely different averages...
And for things like intelligence, I am not convinced IQ tests are that precise on measuring intelligence.
MFA
MFA,
The observed clustering is not just on one or two genes. To define the metric one sums over distance contributions from *all* the genes in the genome. If the clustering were only on a small minority of genes you probably would not get a *resolvable* separation between groups -- i.e., the variation within group A would cover most of group B -- this is *not* the case, in fact the clusters are readily distinguishable.
Think of it this way -- the radius of a given cluster gets contributions from each gene on which there is some variation *within* the group. Suppose that almost all the frequency distributions in groups A and B are identical, except for a small minority of genes. Then the common spread (which contributes to both of the radii of cluster A and B) will likely be much larger than the typical distance between the clusters. That is not what is observed. It's a high dimensional space, so to get resolvable clustering you need a significant fraction of genes to have different distributions.
Of course, we don't have the entire sequence for more than a few individuals, so we can't yet calculate the full distances I've defined for groups. However, studies like Risch's are taking a random sample from the genome at many sites, so it would be very surprising if it wasn't indicative of what you get from the whole thing.
It's still possible that all of the variation in frequency distribution is in genes that *only* influence superficial attributes, but this seems quite unlikely. Look at the link to animal breeding (directed fox and rat evolution) which shows that selection for behavioral traits has superficial effects on appearance (fur, ears, head shape). This suggests that a clean separation as hoped for in H1 is unlikely.
MFA: I forgot to add, it is not that genes for pigmentation necessarily have anything to do with, e.g., disease resistance or cognitive abilities. There need not be a direct connection (although, as in the case with foxes, there might be). The main point is that if two populations have been subjected to different selection effects, they may differ in allele distributions in many distinct genes.
Historically, of course we noticed the superficial phenotype differences first. But the bigger question is what else is clustered and what are the consequences. As I argued above, the data suggests lots of clustering, not just a few genes.
Steve,
Thanks for your patient explanations!
The main point is that if two populations have been subjected to different selection effects, they may differ in allele distributions in many distinct genes.
Historically, of course we noticed the superficial phenotype differences first. But the bigger question is what else is clustered and what are the consequences.
Aha... Now I understand what you mean! This I find quite plausible(from a naive understanding of evolution).
It is then an interesting to study the following questions:
* What are the possible "selection effects"? Are cultural baises(for example, higher respect accorded to certain attributes, which is different in different cultures) also "selection effects"?
* How long does it take for the various selection effects to impact allele distributions in (significantly many) distinct genes?
Have a great weekend.
MFA
Risch et al. Genome Biol. 2002; 3(7): comment2007.1–comment2007.12.
http://www.pubmedcentral.nih.gov/articlerender.fcgi?artid=139378
[MFA's point, and the rejoinder:]
"A forceful presentation of the second point - that racial differences are merely cosmetic - was given recently in an editorial in the New England Journal of Medicine [1]: "Such research mistakenly assumes an inherent biological difference between black-skinned and white-skinned people. It falls into error by attributing a complex physiological or clinical phenomenon to arbitrary aspects of external appearance. It is implausible that the few genes that account for such outward characteristics could be meaningfully linked to multigenic diseases such as diabetes mellitus or to the intricacies of the therapeutic effect of a drug." The logical flaw in this argument is the assumption that the blacks and whites in the referenced study differ only in skin pigment. Racial categorizations have never been based on skin pigment, but on indigenous continent of origin. For example, none of the population genetic studies cited above, including the study of Wilson et al. [2], used skin pigment of the study subjects, or genetic loci related to skin pigment, as predictive variables. Yet the various racial groups were easily distinguishable on the basis of even a modest number of random genetic markers; furthermore, categorization is extremely resistant to variation according to the type of markers used (for example, RFLPs, microsatellites or SNPs).
...
Analysis of variance has led to estimates of 10% for the proportion of variance due to average differences between races, and 75% of the variance due to genetic variation within populations. Comparable estimates have been obtained for classical blood markers [15,16], microsatellites [17], and SNPs [12]. Unfortunately, these analysis of variance estimates have also led to misunderstandings or misinterpretations. Because of the large amount of variation observed within races versus between races, some commentators have denied genetic differentiation between the races; for example, "Genetic data ... show that any two individuals within a particular population are as different genetically as any two people selected from any two populations in the world." [18]. This assertion is both counter-intuitive and factually incorrect [12,13]. If it were true, it would be impossible to create discrete clusters of humans (that end up corresponding to the major races), for example as was done by Wilson et al. [2], with even as few as 20 randomly chosen genetic markers. Two Caucasians are more similar to each other genetically than a Caucasian and an Asian."
MFA: sorry, our comments passed in the ether. Regarding your second one, I can give a very simple, plausible example of selection acting differently on two groups. Note this is just a story - not yet confirmed by data, but it gives the general idea. For more nuanced analysis, you might look at the Cochran-Harpending stuff.
Imagine you have two populations, one which switched from hunter-gatherer to agrarian 5000 years ago, and the other only 500 years ago. You could easily imagine dramatic differences in which combinations of genes are advantageous in the two scenarios. I won't go into details, but there are groups conforming to my example.
There have been recent studies discovering a large number of genes that underwent significant selection over the last 5k years. This means the timescale for selection pressure to act is much less than the 50k years that continental groups have been separated.
See:
Distance Between Strings by Alexander Bogomolny.
"It's a nice feature of the latest word processor programs that they are capable of suggesting
a replacement for a mistyped word. Spelling checkers know how to evaluated distance between a misspelled word and the words in its files. Words whose evaluated distance is the smallest are offered as candidates for replacement. The applet below helps you acquaint yourself with two possible distances between strings. These metric functions attempt to ascribe a numeric (actually, integer) value to the degree of dissimilarity between two strings. That the functions do indeed satisfy the metric axioms can be shown by induction. (Which is a good exercise too.)"
Hamming Distance
"The Hamming distance H is defined only for strings of the same length. For two strings s and t, H(s,t) is the number of places in which the two string differ, i.e., have different characters."
Levenshtein Distance
The Levenshtein (or edit) distance is more sophisticated. It's defined for strings of arbitrary length. It counts the differences between two strings, where we would count a difference not only when strings have different characters but also when one has a character whereas the other does not. The formal definition follows...."
There are more complicated and biologically plausible metrics in the recent literature of, for instance, Proceedings of the [U.S.A.] National Academy of Sciences, taking into account the statstics of different chromosomal mitations, assymetry in losing versus gaining genes.
But this is an approach used by many experts in modern computational biology, genomics, protemics, and so forth.
True, som of us are ex-Physicists!
See also some of my uses of this:
A109809 Primes at Levenshtein distance n from previous value when considered as a decimal string.
2, 3, 11, 223, 1009, 22111, 100003, 2211127, 10000019, 221111257, 1000000009, 22111111123, 100000000019, 2211111111227, 10000000000051, 221111111111197, 1000000000000223, 22111111111111117, 100000000000000003
COMMENT
The Levenshtein distance (also called edit distance) between two strings is equal to the minimum number of insertion, deletion, or substitution operations needed to transform one string into the other. It is named after the Russian scientist Vladimir Levenshtein, who developed this metric in 1965. Levenshtein distance is a generalization of Hamming distance. For positive n, the string length of a(n+1) is always the 1 + the string length of a(n). This sequence is infinite.
REFERENCES
V. I. Levenshtein, Efficient reconstruction of sequences from their subsequences or supersequences, J. Combin. Theory Ser. A 93 (2001), no. 2, 310-332.
LINKS
Michael Gilleland, Levenshtein Distance, in Three Flavors. [It has been suggested that this algorithm gives incorrect results sometimes. - njas]
FORMULA
a(0) = 2, a(n+1) = least prime p such that LD(a(n), p) = n, where LD(A,B) = Levenshtein distance from A to B as decimal strings.
EXAMPLE
a(1) = 3 because we transform a(0) = 2 to 3 (a prime) with one substitution.
a(2) = 11 because we transform a(1) = 3 to the least prime 11 with 1 substitution plus one insertion.
a(3) = 223 because we transform a(2) = 11 to the prime 223 with 2 substitutions plus one insertion, and any smaller prime can be transformed from 11 in fewer than 3 steps.
MATHEMATICA
levenshtein[s_List, t_List] := Module[{d, n = Length@s, m = Length@t}, Which[s === t, 0, n == 0, m, m == 0, n, s != t, d = Table[0, {m + 1}, {n + 1}]; d[[1, Range[n + 1]]] = Range[0, n]; d[[Range[m + 1], 1]] = Range[0, m]; Do[ d[[j + 1, i + 1]] = Min[d[[j, i + 1]] + 1, d[[j + 1, i]] + 1, d[[j, i]] + If[ s[[i]] === t[[j]], 0, 1]], {j, m}, {i, n}]; d[[ -1, -1]] ]];
NextPrim[n_] := Block[{k = n + 1}, While[ !PrimeQ@k, k++ ]; k]; a[0] = 2; a[n_] := a[n] = Block[{q = IntegerDigits[a[n - 1]][[1]], id = IntegerDigits@a[n - 1]}, p = NextPrim[ If[q == 1, Floor[199*10^(n - 1)/90 - 1], 10^(n - 1)]]; While[ levenshtein[id, IntegerDigits@p] != n, p = NextPrim@p]; p]; Table[ a[n], {n, 0, 19}] (* Robert G. Wilson v *)
AUTHOR
Jonathan Vos Post, Aug 16 2005
EXTENSIONS
Corrected and extended by Robert G. Wilson v (rgwv(at)rgwv.com), Jan 25 2006
Or, better yet as it combines words and numbers:
A109382 Levenshtein distance between successive English names of nonnegative integers, excluding spaces and hyphens.
I don't believe in "race" -- let alone in racism, however.
But, when you take biological rhythms into account, there seem to be "eigengenes" -- correlated over frequency space.
Jonathan Vos Post
Jon wrote: "There are more complicated and biologically plausible metrics in the recent literature of, for instance, Proceedings of the [U.S.A.] National Academy of Sciences, taking into account the statstics of different chromosomal mitations, assymetry in losing versus gaining genes.
But this is an approach used by many experts in modern computational biology, genomics, protemics, and so forth."
I just noted the Hamming distance as the simplest possibility. You could certainly try to do better. But I believe that the clustering is robust to any reasonable choice of metric.
It's important to understand the difference between neutral markers and those that confer phenotypic effects (of which, some are subject to darwinian selection). The neutral markers are used in assignment tests like those in the Risch paper. Those neutral markers are excellent for studying population structure. But just because two (or more) populations have significantly different allele frequencies does not mean that they differ in any way at loci that confer phenotypic differences or at any loci that differ due to natural selection.
That's not to say that human populations don't differ at phenotypic/selected loci. But assignment tests aren't useful for studying those loci.
I don't find H2 all that dangerous when you really examine the implications, e.g. Asians are smarter than whites -and here's the g clusters to prove it.
Fine, now science confirms our folk belief. Group pride may take a hit-but it's socio-politically just another generalization, like the presumably unremarkable 'men are stronger than women.'
That 'insight' does nothing for predicting whether THIS man is stronger than THAT woman. If you disagree, go start trouble at a lesbian bar.
Will we ever have a day when the following happens:
'I'm an Askenazi Jew"
'Great-here are the keys to the nuclear reactor'
I doubt it-the individual will always to prove him/herself.
Groups who are less genetically favored for whatever metric can take pride that homo sapiens still kicks the ass of all other primates:
Fire, bitch.
Steve, you are a gem. MFA as well.
Anne
Good grief, my code word is "zamga" :)
This reminds me of a comment made by Richard Dawkins in one of his books. Unfortunately I can't remember which one.
As a thought experiment he hypothesised a "hyper-zoo". It included not just the set of all the animals that have existed, living and extinct, but the super-set of all the animals that possibly could exist. He imagined (if I recall it correctly) evolutionary history could be mapped out as a track through this imaginary zoo.
It's an interesting idea. It could be proposed as genetically based or you could look at it from the phenotype end as a kind of "n dimensional" cline map with n being the number of features being mapped.
Presumably humans would be a branch within the hyperzoo too. The clusters you mention would be there too.
Here is an interesting speculation. Taking Dawkins idea of evolutionary history as a track through the hyperzoo, the clusters can be thought of as dynamic systems. So are we talking about "attractors" here or just simple coincidences?
"'I'm an Askenazi Jew"
'Great-here are the keys to the nuclear reactor'
I doubt it-the individual will always to prove him/herself."
That's one of the technological extrapolations in the fine science fiction film GATTACA [1997]:
(1) complete identification of an individual from instant DNA analysis of a drop of blood, eyelash, urine sample, skin falke;
(2) parental selection of oprimized child from their DNA;
(3) Said optimum child further modified near conception to eliminate all known diseases.
There are no Curriclum Vitae in that dystopian future. The candidate's DNA is used to determine if he/she is of the genetic master-race, or a old fashoned homo sapiens. Protagonist wants to be on manned mission to Titan; DNA testing limits him to being a janitor. Then the plot gets clever...
My son insists that this is a dystopia that many in the population see as utopia. He says this is a de factor prequel to Blad Runner, by which time the DNA manipulation has lked to creating replicants superior to humans in all ways (except they're sterile and live 5 years); and manned solar system exploration has evolved to interstellar colonization and war.
-- Prof. Jonathan Vos Post
From a large 1935 Websters dictionary my family had in 1954 I got a look into regional Europe, very much like tribal Africa with distinct physical characteristics in local identities. South Sea Islanders count over 300 different separate ethnic identities. The same throughout Asia. And if you did not know, there is a other white column in San Francisco schools. If you take this H2 view out to its best in region, I think some tribes or regions will rate higher than others. You have to think smaller in gifted champions of race, the Serbs can get it, most of tribal Africa can see it, and all of the rest of the world has that view. And if you look into history a local brilliance has often shined over the whole area about them. We in California are bright because we have imported the best tribal and regional talent of the world. I would bet as a general rule that overseas Chinese come more from one area in China than the general population and they have a step up on the general Chinese populations intellect. Try regional talent over full population.
Racial clustering in genetic space becomes distinctive only when a certain number of genes are considered. Similarly, racial clustering in phenotype space will become distinctive only when more than a few phenotypic attributes are considered.
In others words, considering a certain gene named CLUZ, given your racial profile, I cannot guess with confidence which allel of CLUZ you actually have.
Similarly, considering a particular trait such as Stupidity, given my racial profile, you cannot guess what my value of this trait actually is.
H2 does not diminish our individuality. It's not dangerous. H1 is more dangerous because it's so plain stupid yet widely accepted. It's a superstition. We are all less enlightened because of such stupidity being promoted.
Professor Post,
I found Gattaca unlikely from an economic perspective. Say for simplicity's sake, that the DNA analyses are solely for intelligence. The employer is screening for a trait he thinks relevant to productivity in the job. Even in the case where genetic engineering has bestowed an advantage most of the time, there is still some tall ones to be found among the 'naturals.' Discrimination of the sort in the movie would be like not hiring any Asians because whites (and blacks) are taller, on average. But what about Yao? On any given trait, there is talent however defined among all groups, just to varying frequencies.
There are (at least) two possible responses, though both are rather implausible- either that the average difference is so large that the threshold for a given trait is passed by so few naturals as to make it not worth examining them. Or, that those in power, the 'modifieds,' deem themselves wholly superior and are loyal only to their own - they are synthetic supremacists.
I do think the vision of Gattaca is plausible in another respect, in that there will be two classes, of the engineered and the naturally born. There are now methods for screening a fetus for certain genetic conditions, known as Preimplantation Genetic Diagnosis, which will eventually come to include genes for intelligence. Some will have children through this method, while others won't, especially those already having children due in part to negligence, i.e. the quarter of children born out of marriage.
Did you submit your site at blogsearch.sg?
You can reach blogsearch by just typing blogsearch.sg in your browser window or click here
This is a service by bizleadsnet directory of web logs.
ENGINEERING
These comments have been invaluable to me as is this whole site. I thank you for your comment.
Why do fear facts and statistics.
What you really fear is that people don't understand distributions and don't understand that a distribution talks about a range of values. Instead they tend to believe everything is the mean.
Well fooey, buck up and realize that your liberal ideals already handle the case where you're not born equal, you're made minimally equal by rights.
Mr. Hsu,
Please consider the following:
You have made only a case for genomic clustering. You have made no such case for it as a basis of racial categorization. Your statement,"Racial categorizations have never been based on skin pigment, but on indigenous continent of origin" is quite irresponsible. Racial categorizations HAVE ALWAYS BEEN ABOUT SKIN PIGMENT. Hundreds of years before anyone knew what a genome was, folks were dehumanzing other folks due to their skin color, (along, of course, with other factors, like what king or religion they were allied to. And, these were allied to geography, but, not in any vauge "continet of origin way". Was Ghengis Khan's primary motivation to invade Europe because the folks there were of a "continent of different origin"?
You use all this gene science to make pontifications about "race", however, your basic notion of what informs the concept of race is fallable.
Undoubtly, there is no separation of history and biology (it could not be otherwise). But, you are purporting to use the evidence of clustering to somehow give creedence to the concept of "race", when race as it historically relates to humans, has NEVER been about the disticntions within a species due to geographic distance. Race has ALWAYS been about the superficial distinctions in which one group formed a basis to dehumanize an other.
All "scientific" notion of classifying life from Artistotle to Robert Hooke has been based on the superficial trait. So now you have some clustering data and attempt to validate not only the superficial but the ignorant as well.
Again, what you have is evidence of clustering, extremely vital important data to make life saving use of, and nothing more.
I find it diffucult to believe you aren't already cognizant of this. But, for arguement's sake, let's say you're not. Well then, wise up, chum.
"heynow said...
You have made only a case for genomic clustering."
Which suggests that there is a biological basis for common sense notions of race/ethnicity.
Did the sociology department run out of donuts and coffee? C'mon and git now lil' doggie!
Muddled
Post a Comment